本文同步發表於我的 GitHub page
前言:
回顧一下R-CNN的問題點:
- 訓練分太多階段
- 訓練消耗太多硬體資源和時間。因為每次要取BBox的feature vector,都需要將每一張影像的region proposals的執行一次CNN,並且將vector存到硬碟上。
- 對一張影像進行detection需要47秒的時間(on GPU)
所以,繼R-CNN之後,為了讓速度、精度表現更加出色,所以作者很快的就修改了運算上的順序、結構性的問題、簡化model的設計來提昇運算速度,上detection的表現上升到了2s/image。
論文:
Fast R-CNN
演算法結構:
Fast R-CNN的架構如下圖所示:
基本上,重要的改變有:
- 拿掉SVM結構,改以softmax作為Classification的NN
- 一樣是用selective search提出Region Proposals,或叫做ROI (Region of Interest),但是改為先將整張影像通過conv.得到feature map後,將ROI映射在map上來取真正要用的ROI,因此一張影像只須過一次Convolution,也就節省掉很多的計算和硬體資源。
- 利用ROI pooling layer來統一ROI送進Fully-connected layer (FC)層前的維度。
以下就自架構圖的下到上說明各部件的的細節。
> Region Proposals:
這裡一樣是使用selective search的方式提出2000個region。不過,並不是將原始影像依據region來切割後送入backbone network中的。而是將region映射到CNN最後的feature map上才切出我們真正要拿來使用的ROI。

> Backbone Network - VGG16:
這次到了Fast R-CNN,backbone的部份換成了VGG16。而在最後一層convolution block的最後一個conv.所得到的feature map (shape=14*14*512),就是剛剛ROI要映射到的目標層,所以這裡的ROI才是我們真正要使用的。
但是,ROI的長寬不一樣要怎麼辦呢?所以作者將原本接的最後一個pooling layer取代掉,換成可以將size固定的ROI Pooling layer。

> ROI Pooling Layer
ROI可能是很多不同的長寬構成的框框,而VGGnet的FC層要以7x7的feature map為輸入,所以在ROI pooling layer中,我們要做的事就是「在14x14的feature map上,切出ROI後,以pooling手法將ROI輸出成7x7」。
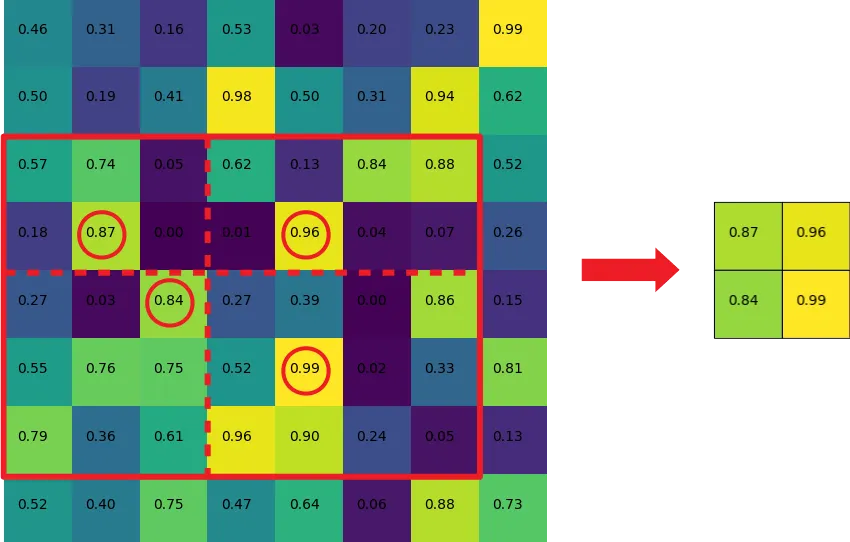
這個層的機制,我就用下圖來舉個例子直覺說明。假定今天要在一個8x8的map上做ROI pooling,如下圖。

若今天Region proposal映射到這個map上的尺寸是7x5(如下圖紅框),且我們要將ROI輸出成2x2的大小,就會將下圖的紅框分割成2x2(如下圖虛線,因為長寬7,5無法被2整除)。接著就可以透過max-pooling來取值。
> Detector:
在後面的分類器,從FC層後分成兩支進行,第一支是分類器,由原本的SVM改成了FC層的softmax。特別注意到的是,分類的類別數量因為要讓背景獨立成一個類別,所以是K+1個。而第二支就是bbox regressor,則是沒什麼變化。
> Loss:
因為分類器都變成了整個網路中的一部分,所以作者就設計了一套整合所有目標的loss function:

其中,
p:K+1個類別的分類機率
u:目標類別
tu:則是如同R-CNN中所述的預測的bbox和groud-truth之間的offsets
v:ground-truth box
所以,Lcls就是分類部份的loss,是對與真實目標的誤差取-log。而[u>=1]標誌的意思是,若u>=1則為1,反之則為0。也就是說如果一個ROI落在背景的區域而沒有物體,則值等於0,也就不用考慮到bbox的誤差Lloc。
而Lloc的式子如下:

他是採用smooth L1的損失函數設計,為的是讓函數對離群值得反應不要那敏感。
簡單用下面這張圖來看,因為一般採用L2的損失函數,會因為平方的關係而使得誤差反應被離群值主導。採用Smooth L1,除了在0值附近以0.5的倍數降低反應以外,在大於1以外的離群值部份,就採用線性的方式表示,來將誤差的呈現趨於平緩。因此雖然L2的函數通常收斂較快,但也同時需要一個較好的起始點,才能避免函數無法收斂。然而Smooth L1就是讓它順順的收斂,比較不容易讓誤差爆炸。

總結
到這邊,算是講完Fast R-CNN的架構思路。也因為這些調整,讓Fast R-CNN的速度比R-CNN的速度快上25倍之多。最後我們再總結一下Fast R-CNN的重點:
- 改變ROI sampling的邏輯,讓原本要重複運作2000次的特徵提取,變成只對原始影像做一次特徵提取,而讓原圖上的region proposals映射到feature maps上做sampling。
- ROI pooling層統一ROI送進FC層的維度。
- 使用多目標的loss function,使得原本R-CNN的多層訓練變成簡單的back-propagation。
這些進步,讓Fast R-CNN的mAP也比R-CNN略高一點,但速度加快很多(2s/image)。而且訓練的速度也增加了將近9倍的時間(9.5hr)。
當然它還是有缺陷的。
其實測試的時間並沒有含括提出proposals的時間,所以納入了selective search在提出proposals的過程,其實表現還遠遠不足以應用。因此,後人提出了將region proposals的部份,也用NN一併解決,整合進網路中,也就誕生了Faster R-CNN。
以上是我個人對這篇論文的消化,如果有錯誤之處,請各位朋友指教或幫我指出,謝謝!
